好久没有更新博客了,最近又抽时间重新安装了系统,这次选择的是Windows Vista 64位版本,终于可以认全我的4G内存了。我这段时间运气也是特别的好,刚好碰到WMware Workstation推出6.0版,在网上很容易就能够下载到,因此,又使用VMware虚拟了一个机器,安装了最新的红旗桌面6.0,同时,Microsoft Virtual PC这个难用的产品正式退出我的历史舞台。因为我经常重新分区重装系统,以前的源代码往往无影无踪,所以在这里向找我索要代码看的兄弟们道个歉。不过,这样的历史不会重演了,因为我对现在的分区方案、64位系统以及虚拟机非常满意,就算是系统崩溃需要重装,也不会轻易重新分区,所以基本上不会发生资料丢失这样的事情了。
另外一件值得和大家分享的事,就是我在2007年10月7日晚10点10分当爸爸了,我老婆生的是个男孩,兄弟们祝贺我吧。以后,我上网的时间将会比以前少一些,更新文章要慢一些,但是我一定会尽我最大的努力,希望大家多来我的博客捧场。
这是我的第三十一篇随笔,本来,我在写完第三十篇就想:等所有的随笔阅读量都超过1000后我再写新的,但是我发现,如果长时间没有随笔在首页露面,这访问量是上不来的。于是,就有了这个系列。
下面开始正文吧,新的系统,新的图片,希望为大家带来新的体验。首先,重申一下我的基本环境。
1、JDK,我选用的是5.0 Update 12,现在在Sun的下载页面已经看不到了,因为现在可以看到的是Update 13。要下载我用的这个老版本的,可以参考下面的网址:
2、IDE,我选用的是Eclipse 3.2.2,同样的,这个版本也已经过时了,在下载页面已经看不到了。我选用这个版本的唯一原因,就是因为Eclipse的多国语言包最新还是3.2.1版的。喜欢复古的朋友,可以参考下图中的下载地址:
语言包可以直接在下载页面看到,如下图:
3、Subversion的客户端工具,我这里选择的是Subclipse,它是一个Eclipse的插件,使用起来很方便的。下载地址参考下图:
下面,我们正式进入Subversion的世界。看过我前面的文章以及评论的朋友,可以看到,使用过Subversion的朋友,他们对CVS是大大的不以为然的。为什么Subversion会有这么大的魔力呢?要全面了解一个软件,必须的从最简单的体验入手,在这里,我们就简单地体验一下Subversion客户端的使用。
客户端工具我们刚才已经介绍了,还需要找一个服务器才能完成我们的体验。这个不难,因为很多开源项目都是使用Subversion进行源代码管理,我在这里选择我最熟悉的一个,那就是SpringSide。地址如下图:
看到这里,细心的朋友可能要问:为什么这个地址那么像是一个网页的地址,连协议都是http?我来做个小小的解释,Subversion服务器软件很多样化,有一种是单独的守护程序,使用svn协议,还有一种是一个httpd服务器的模块,配合httpd服务器来提供Subversion服务,使用的是http协议。
把上面这个地址复制下来,然后打开Eclipse,新建项目,选择SVN分类中的从SVN检出项目,如下图: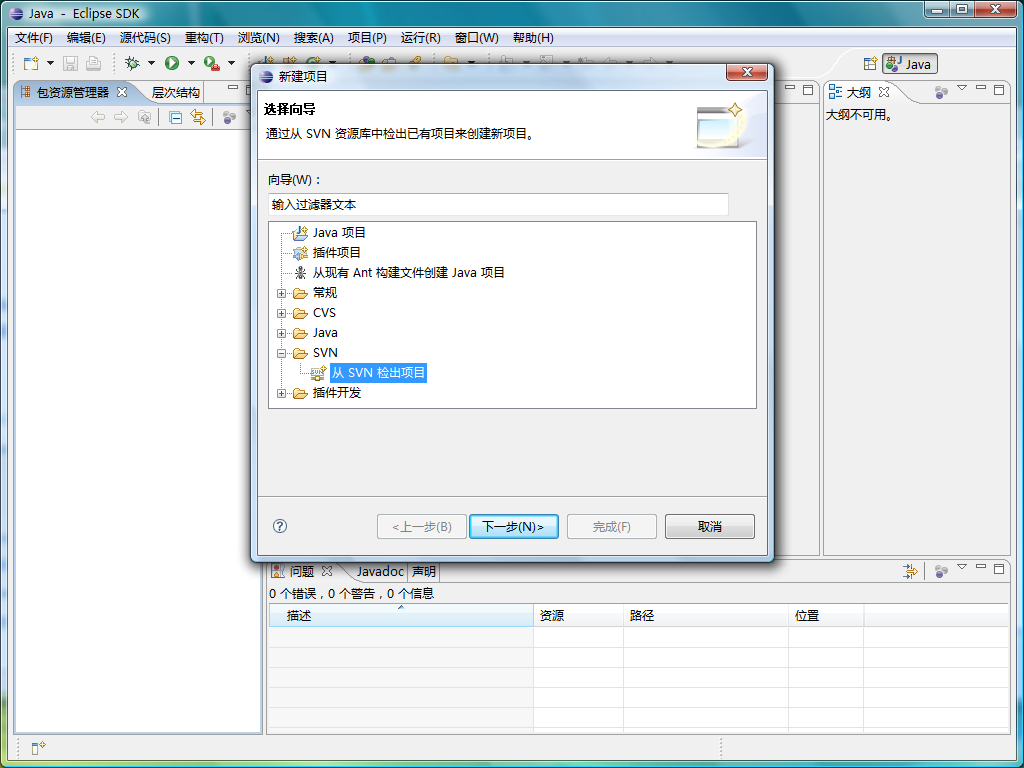
点下一步,将刚才复制的URL粘贴到这里:
点下一步: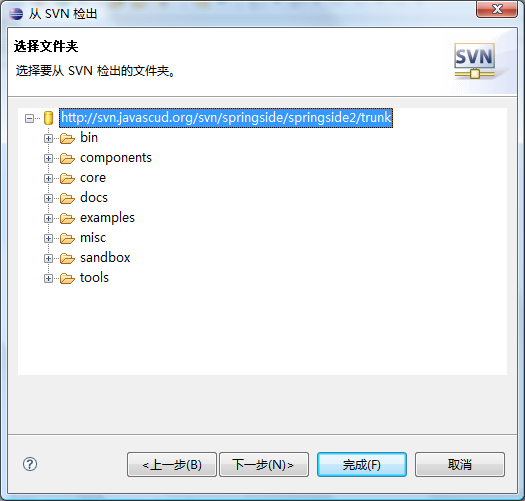
再下一步: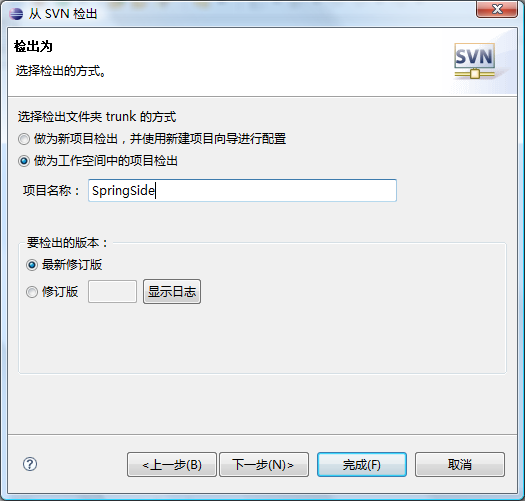
再下一步,检出操作需要点时间,请耐心等待:
项目检出之后,就可以在Eclipse中查看它的源代码了,如下图:
由于我不是SpringSide的开发人员,所以我只能够执行简单的check out操作,优点就是可以随时看到最新的代码(不过好像现在SpringSide更新很慢)。如果要执行更多的管理操作,我们必须有一个具有更多权限的Subversion服务器,最简单的办法就是自己建立。下一篇,我将向大家展示怎么自己建立一个Subversion服务器。
Friday, November 23, 2007
使用Subversion进行源代码管理(一):体验Subversion客户端 - 海边沫沫 - BlogJava
Wednesday, November 21, 2007
使用XMLBeans处理XML数据和文档入门 - 陈建慧的程序人生 - CSDNBlog
| 时间:2004-03-03 作者:powerise1 浏览次数: 2603 本文关键字:xml, xmlbeans, ant, schema |
|
XMLBeans是Bea公司针对XML处理的一个项目,现在已经提供免费下载和使用,目前的最新版本是1.0。
1 为什么使用XMLBeans
在XMLBeans之前,我们访问xml数据和文档有两种选择:
1. 使用DOM、SAX来访问XML数据和文档的内容
2. 使用JAXB等技术将XML映射为java类
不管你使用哪一种,你都无法完整的访问该XML数据和对象的丰富内容和Schema信息。产生的原因是因为java数据模型和XML之间不匹配造成的,所以应用中你要不就选择了可扩展性,要不就只能选择系统的强壮性。
随着XMLBeans的出现,我们不需要再采取这种折衷的措施了。XMLBeans提供了更多的特性来访问XML数据和文档:
1. XMLBeans是基于标记流,因此可以轻松的使用指针在xml数据和文档之间导航。指针接口适用于所有xml数据和文档。
2. 如果你的xml数据和文档有一个schema的话,XMLBeans将给您生成这些XML数据和文档的java类“视图”(也就是访问这些XML数据和文档的java代码)。
3. 开发者可以使用这些java代码轻松的读/写xml数据和文档,而且被强制的执行xml schema中规定的一些约束。
4. java类“视图”都能够忠实的表述原始xml数据和文档的内容,因为java类“视图”都是基于受保护的、最基本的xml表现。
所以使用XMLBeans来访问xml 数据和文档的好处是显而易见的:
1. 完全使用面向对象的观点来看待和处理数据和文档
2. 开发者不再需要编写大量的代码来访问XML数据和文档
3. 可以使用schema中规定的对于数据的约束条件,而不需要自己去编写实现这些约束的代码
4. 不需要解析所有的xml数据和文档而仅仅是为了访问其中的某个数据项
关于XMLBeans更详细的情况请大家访问http://dev2dev.bea.com/technologies/xmlbeans/
2 环境和工具准备
XMLBeans中的大量工作使用了Ant工具,所以再开始工作之前请下载Ant工具并使它正常运行。
XMLBeans的java实现请大家到bea的网站上下载:http://dev2dev.bea.com/technologies/xmlbeans/index.jsp
在执行过程中,还需要用访问xml的dom组件,也就是xml-apis.jar文件,可到http://xml.apache.org/xerces2-j/index.html下载。附件中的test-XMLBeans.rar文件中也有这个jar文件。
3 第一个例子
3.1 实例说明
我们这里使用一个订单的例子,他的实例文档如下:
<po:purchase-order xmlns:po=" http://vivianj.go.nease.net/easypo ">
<po:customer>
<po:name>Gladys Kravitz</po:name>
<po:address>Anytown, PA</po:address>
</po:customer>
<po:date>2003-01-07T14:16:00-05:00</po:date>
<po:line-item>
<po:description>Burnham's Celestial Handbook, Vol 1</po:description>
<po:per-unit-ounces>5</po:per-unit-ounces>
<po:price>21.79</po:price>
<po:quantity>2</po:quantity>
</po:line-item>
<po:line-item>
<po:description>Burnham's Celestial Handbook, Vol 2</po:description>
<po:per-unit-ounces>5</po:per-unit-ounces>
<po:price>19.89</po:price>
<po:quantity>2</po:quantity>
</po:line-item>
<po:shipper>
<po:name>ZipShip</po:name>
<po:per-ounce-rate>0.74</po:per-ounce-rate>
</po:shipper>
</po:purchase-order>
我们使用下面的schema来描述这个实例文档:
<xs:schema
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:po="http://vivianj.go.nease.net/easypo"
targetNamespace="http://vivianj.go.nease.net/easypo"
elementFormDefault="qualified">
<xs:element name="purchase-order">
<xs:complexType>
<xs:sequence>
<xs:element name="customer" type="po:customer"/>
<xs:element name="date" type="xs:dateTime"/>
<xs:element name="line-item" type="po:line-item" minOccurs="0" maxOccurs="unbounded"/>
<xs:element name="shipper" type="po:shipper" minOccurs="0" maxOccurs="1"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:complexType name="customer">
<xs:sequence>
<xs:element name="name" type="xs:string"/>
<xs:element name="address" type="xs:string"/>
</xs:sequence>
<xs:attribute name="age" type="xs:int"/>
</xs:complexType>
<xs:complexType name="line-item">
<xs:sequence>
<xs:element name="description" type="xs:string"/>
<xs:element name="per-unit-ounces" type="xs:decimal"/>
<xs:element name="price" type="xs:decimal"/>
<xs:element name="quantity" type="xs:integer"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="shipper">
<xs:sequence>
<xs:element name="name" type="xs:string"/>
<xs:element name="per-ounce-rate" type="xs:decimal"/>
</xs:sequence>
</xs:complexType>
</xs:schema>
现在,要访问的xml数据已经确定了,而且已经用schema来描述他了,剩下的就是使用XMLBeans来辅助生成访问XML数据的java代码了,下面的章节将详细的介绍这部分内容
3.2 ant辅助生成访问XML数据的java代码
3.2.1 外部jar文件
在使用XMLBeans生成访问XML数据的java代码时,我们需要用到xbean.jar文件,下载的XMLBeans里面有这个文件。
3.2.2 增加的taskdef
编译脚本执行时候必须增加一个XMLBean的taskdef,内容如下:
<taskdef name="xmlbean" classname="com.bea.xbean.tool.XMLBean" classpath="path/to/xbean.jar"/>
3.2.3 xmlbean
使用xmlbean标签来生成访问xml数据的java代码,简单的例子如下:
<xmlbean schema="schemas" destfile="Schemas.jar"/>
<xmlbean schema="schemas/easypo.xsd" destfile="Schemas.jar" srcgendir="." />
第一个例子表示为schemas下面所有的*.xsd文件生成访问代码,将所有的代码编译好后放入Schemas.jar文件中。
第二个例子表示为schemas下面所有的easypo.xsd文件生成访问代码,将所有的代码编译好后放入Schemas.jar文件中,而且将生成的。Java文件放在当前目录下。
其中的参数简单的说明如下:
xmlbean 标签表示这是要生成指定schema文件的访问代码。
Schema 属性表示要生成访问代码的xsd文件的范围,可以是一个目录,也可以
是一个文件或者使用fileset进行定义。
Destfile 属性定义了被生成的代码编译后将放在那个文件中。
Rcgendir 属性则表示生成的。Java文件将放在那个目录中。
Xmlbean标签支持的其它参数和相关的说明请参考XMLBeans的帮助文档,这里不作过多的说明。
3.2.4 实际的build.xml
<project name="MyProject" default="compile" basedir=".">
<property name="src" value="."/>
<property name="build" value="build"/>
<property name="dist" value="dist"/>
<property name="classpath" value="./xkit/lib/xbean.jar "/>
<target name="init">
<!-- Create the build directory structure used by compile -->
<mkdir dir=""/>
</target>
<target name="compile" depends="init">
<!-- Compile the java code from into -->
<taskdef name="xmlbean" classname="com.bea.xbean.tool.XMLBean" classpath=""/>
<xmlbean schema="schemas/easypo.xsd" classpath="" destfile="easypo.jar" srcgendir=""/>
</target>
</project>
3.2.5 生成jar文件
现在你可以进入build.xml文件所在的目录,执行ant -f build.xml来生成所有访问该easypo.xml的代码。
执行完以后,这个目录下面会多出一个Schemas.jar文件,他包含了所有被生成和编译了的、访问xml文档的.class文件。目录下面会多出一个net目录,他的子目录下包含了所有被生成的.java文件.实际的jar文件构成请大家参考作者提供的Schemas.jar文件.
4 测试一下
4.1 测试代码
好了,现在我们来写个例子,测试一下是否可以成功的访问xml数据.完整的代码请参看
//解析xml实例文档,他的参数poFile是一个file类型的参数
//所以需要我们将3.1的实例文档保存为一个.xml文档
PurchaseOrderDocument poDoc =
PurchaseOrderDocument.Factory.parse(poFile);
//创建一个访问该xml实例文档的接口PurchaseOrder
/**[注] 让作者感到很意外的是,bea提供的例子代码中这段的定义是这样的:
*PurchaseOrder po = poDoc.getPurchaseOrder();
*也就是说PurchaseOrder这个接口应该是一个单独的类,但是作者查看XMLBeans
*最后生成的.java文件中,这个PurchaseOrder却是作为PurchaseOrderDocument的一
*个内部类出现的
*/
PurchaseOrderDocument.PurchaseOrder po = poDoc.getPurchaseOrder();
//直接过去其中的所有lineitem子元素的所有内容,他返回一个lineitem对象的数组.
LineItem[] lineitems = po.getLineItemArray();
System.out.println("Purchase order has " + lineitems.length + " line items.");
double totalAmount = 0.0;
int numberOfItems = 0;
//直接使用对应的get方法来获取对应属性的值
for (int j = 0; j < lineitems.length; j++)
{
System.out.println(" Line item: " + j);
System.out.println(
" Description: " + lineitems[j].getDescription());
System.out.println(" Quantity: " + lineitems[j].getQuantity());
System.out.println(" Price: " + lineitems[j].getPrice());
numberOfItems += lineitems[j].getQuantity().intValue();
totalAmount += lineitems[j].getPrice().doubleValue() * lineitems[j].getQuantity().doubleValue();
}
System.out.println("Total items: " + numberOfItems);
System.out.println("Total amount: " + totalAmount);
4.2 测试结果
运行这段代码,应该在控制台打印如下信息:
Purchase order has 3 line items.
Line item 0
Description: Burnham's Celestial Handbook, Vol 1
Quantity: 2
Price: 21.79
Line item 1
Description: Burnham's Celestial Handbook, Vol 2
Quantity: 2
Price: 19.89
Total items: 4
Total amount: 41.68
5 总结
XMLBeans是Bea公司的一个公开源代码项目,以Schema为基础建立的、访问xml的一种解决方法,提供了访问和处理xml数据和文档时既可以完全的访问xml的内容、又不丢失xml的schema信息的强大功能。使用XMLBeans可以让您用面向对象的观点来对待和处理xml数据和文档,同时又可以忠实于该xml数据对应的xml结构和schema。
本文中作者简单的介绍了XMLBeans,并且给出了一个简单的例子,详细的演示了如何配置XMLBeans,如何使用他的ant扩展辅助生成访问xml的java代码,如何编写客户端来测试该段代码是否成功执行的全过程。希望能够让大家掌握如何使用XMLBeans来简化各自的开发工作、提高自己的开发速度。XMLBeans的高级应用将在接下来的文章中介绍。
参考资料:
1. ANT的帮助 http://ant.apache.org/
2. XMLBeans的帮助 http://dev2dev.bea.com/technologies/xmlbeans/
工具下载:
1. ANT工具下载 http://archive.apache.org/dist/ant/binaries/
2. XMLBeans下载 http://dev2dev.bea.com/technologies/xmlbeans/
作者的所有工作文件: test-XMLBeans.rar
作者信息:
姓名: 肖菁
联系方式: 0731-6665772,jing.xiao.com
简介: 作者目前是湖南省长沙铁道学院科创计算机系统集成有限公司软件中心软件工程师,IBM developerworks/BEA dev2dev撰稿人,主要研究J2EE编程技术、Web Service技术以及他们在websphere、weblogic、apache平台上的实现,拥有IBM 的 Developing With Websphere Studio证书。欢迎大家访问作者的个人网站: vivianj.go.nease.net
Trackback: http://tb.blog.csdn.net/TrackBack.aspx?PostId=565849
XMLBeans实例:地址簿 阅 - NETBIRD的专栏 - CSDNBlog
| XMLBeans介绍 XML已经迅速成为网络上事务处理的通用语言(lingua franca)。它是Web服务概念的基础,并且被广泛地应用在电子文档的交换中。用于处理Java应用中XML的第一代工具,基于文档对象模型(DOM)、XML的简单API(SAX)及XML解析器,分别完成各自的任务。然而,第一代技术没有充分利用Java语言的灵活性和强大性。 BEA Systems最近推出了一项叫做XMLBeans的新技术,它为在Java中处理XML提供更自然的、更直观的、更有力的处理机制。XMLBeans的名字是由XML(这很明显)加上JavaBeans得出来的,因为XMLBeans借用了JavaBeans组件体系结构中流行的属性样式。 当XMLBeans的8.0版本在2003年发布后,它的使用将贯穿整个WebLogic平台。但是这项技术本身能够单独运行,并且BEA已经发布了一项Web服务,允许在你选择的XML模式中试验XMLBeans。你提交模式(.xsd)文件(或是包含多个相关模式的ZIP文件),然后Web服务返回一个JAR文件,这个JAR文件包含针对模式的XMLBeans类以及支持XMLBeans API。稍后,我将在本文中演示怎样使用这项服务。你可以在BEA dev2dev开发者站点的XMLBeans Technical Track中阅读XMLBeans Service。 我在文中给出的例子论证了XMLBeans的一个独特的特征:XMLBeans模式编译器专为你的模式生成的强类型模式类型系统API。XMLBeans也被用于无模式的方案操作中。为得到更多的关于XMLBeans性能的内容,请参见XMLBeans Overview Page。 什么是XML模式? 虽然XML模式可以用于创建内容任意的XML文档,但它更感兴趣的(而且必需)是定义特定类型的文档。例如,如果每个公司都能为购买订单定义它自己的电子文档格式,电子商业将不会走得很远。XML支持正式文档类型的定义,在这些类型的基础上可以验证其他任何特定的文档。 在XML还不成熟的时候,有人在文档类型定义(DTD)文件中定义了一个文档类型。在DTD文档中,你可以指定能够存在于实例文档中的元素类型,元素必须被安排好,对于数值元素来说,还必须有值的范围样的限制。但是DTD文档也有许多缺点,最大的缺点是DTD文档用一种离奇的语言而不是用XML语言本身来表达。 现在定义XML文档的方法是使用XML模式。XML模式的用途和DTD文档一样,只不过是它用XML语言表达的。这意味着你可以用标准的XML工具创建、编辑以及操纵XML模式。 XML模式规范(可以在http://www.w3.org/XML/Schema中找到)还定义了一列可以用模式表达的46种特定数据类型,其中包括字符串、整型、浮点型、日期等更多的类型。因此,XML模式可以利用丰富的类型系统来反映了现代编程语言中可用的新技术。 本文描述的例子使用了两种类型的XML文档:联系人(contact)和地址簿(address book)。其中地址簿可以包含联系人。 contactUsa.xsd模式 XML模式通常存放在扩展名为.xsd的文件中,这是由于XML模式定义(XML Schema Definition)的首字母缩写为xsd。下面是一个来自contactUsa.xsd(本文提到的所有文件在AddressBookApp.zip中都可以找到)文件的XML模式例子。这个模式为地址簿中的条目(联系人)定义了格式。为简单起见,这个模式中用到的邮政地址都是按照美国的习惯表示的。 <xs:schema targetNamespace="http://dearjohn/address-book" xmlns:xs=http://www.w3.org/2001/XMLSchema xmlns:address-book="http://dearjohn/address-book" elementFormDefault="qualified"> <xs:element name="contact"> <xs:complexType> <xs:sequence> <xs:element name="family-name" type="xs:string"/> <xs:element name="given-name" type="xs:string"/> <xs:element ref="address-book:mailing-address" minOccurs="0" maxOccurs="2"/> <xs:element ref="address-book:phone-number" minOccurs="0" maxOccurs="3"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="mailing-address"> <xs:complexType> <xs:sequence> <xs:element name="address-line-1" type="xs:string"/> <xs:element name="address-line-2" type="xs:string" minOccurs="0"/> <xs:element name="city" type="xs:string"/> <xs:element name="state" type="address-book:state"/> <xs:element name="zipcode" type="address-book:zipcode"/> </xs:sequence> <xs:attribute name="location" type="xs:string"/> </xs:complexType> </xs:element> <xs:element name="phone-number"> <xs:complexType> <xs:sequence> <xs:element name="area-code" type="address-book:area-code"/> <xs:element name="local-phone-number" type="address-book:local-phone-number"/> </xs:sequence> <xs:attribute name="location" type="xs:string"/> </xs:complexType> </xs:element> <xs:simpleType name="area-code"> <xs:restriction base="xs:string"> <xs:pattern value="[0-9]{3}"/> </xs:restriction> </xs:simpleType> <xs:simpleType name="local-phone-number"> <xs:restriction base="xs:string"> <xs:pattern value="[0-9]{3}-[0-9]{4}"/> </xs:restriction> </xs:simpleType> <xs:simpleType name="state"> <xs:restriction base="xs:NMTOKEN"> <xs:enumeration value="AL"/> <xs:enumeration value="AK"/> ... <xs:enumeration value="WI"/> <xs:enumeration value="WY"/> </xs:restriction> </xs:simpleType> <xs:simpleType name="zipcode"> <xs:restriction base="xs:string"> <xs:pattern value="[0-9]{5}(-[0-9]{4})?"/> </xs:restriction> </xs:simpleType> </xs:schema> 在XML方案中有两种基本类型的元素:简单类型和复杂类型。简单类型定义的元素有值但没有子元素,复杂类型定义的元素可以有子元素。在上面的模式中,<contact>被定义为一个复杂元素,该元素可以(在本模式中实际上必须)有子元素<family-name>和<given-name>,还可以有类型<mailing-address>和<phone-number>的子类型。 我不想在XML模式上用太多的篇幅,它是一个复杂的主题而且关于这个主题有许多好书可以利用。但是这里有一些关于定义在contactUsa.xsd中模式的声明,即使你不熟悉XML模式,它也有助于你理解。下面是这些声明: contactUsa.xsd中定义的所有元素都在XML名字空间http://dearjohn/address-book中。targetNamespace声明定义了用于该模式(在schema-speak中叫做"全局"元素)中顶级元素的命名空间。 elementFormDefault="qualified"规范意味着本方案中的所有非全局性元素也在目标命名空间中(只要它们没有明确说明位于其他的命名空间)。在模式文件中指定elementFormDefault="qualified"几乎总是一个好主意:你一般不想让同一个模式中的全局性和非全局性元素处于不同的命名空间。 <contact>总是包括名称字段,并且可以包含最多两个<mailing-address>元素和最多三个<phone-number>元素,这是可选的。 <mailing-address>必须总是按照顺序包含<address-line-1>、<city>、<state>和<zipcode>子元素。<mailing-address>可以在子元素<address-line-1>后紧跟一个子元素<address-line-2>。 <mailing-address>和<phone-number>元素都有位置属性,然而在这个模式中没有表示出来,目的是为了让位置容纳类似于"home"和"work"这样的值。 所有<area-code>、<local-phone-number>和<zipcode>元素的值被限制为特定的文本样式。 所有<state>元素的值被限制在50个州的缩写加上哥伦比亚区的列举范围内。 下面的XML文档遵照的是contactUsa.xsd模式: <?xml version="1.0"?> <contact xmlns="http://dearjohn/address-book"> <family-name>Smithers</family-name> <given-name>Bill</given-name> <mailing-address location="home"> <address-line-1>1500 Dexter Ave.</address-line-1> <city>Seattle</city> <state>WA</state> <zipcode>98109</zipcode> </mailing-address> <mailing-address location="work"> <address-line-1>501 Pike St.</address-line-1> <address-line-2>Suite 2900</address-line-2> <city>Seattle</city> <state>WA</state> <zipcode>98101</zipcode> </mailing-address> <phone-number location="home"> <area-code>206</area-code> <local-phone-number>441-1695</local-phone-number> </phone-number> <phone-number location="mobile"> <area-code>206</area-code> <local-phone-number>778-9218</local-phone-number> </phone-number> </contact> addressBook.xsd模式 除了上面描述的contactUsa.xsd模式外,文中后面给出的地址簿的例子使用在addressBook.xsd中定义的如下模式: <xs:schema targetNamespace="http://dearjohn/address-book" xmlns:xs=http://www.w3.org/2001/XMLSchema xmlns:address-book="http://dearjohn/address-book" elementFormDefault="qualified"> <xs:include schemaLocation="contactUsa.xsd"/> <xs:element name="address-book"> <xs:complexType> <xs:sequence> <xs:element ref="address-book:contact" minOccurs="0" maxOccurs="unbounded"/> </xs:sequence> </xs:complexType> </xs:element> </xs:schema> 这个模式非常简单:它定义了一个<address-book>元素,此元素可以包括0或来自contactUsa.xsd模式的更多<contact>元素。 用XMLBeans服务生成XMLBeans 既然已经定义了这些模式,就可以使用在线XMLBeans服务来针对模式生成XMLBeans类型系统(Java API)。 由于有两个相关的模式文件,那么我可以把它们压缩到一个ZIP文件中去,以便上传。然后在XMLBeans服务Schema Upload Page中的"要上传的模式或ZIP文件"域指定ZIP文件。服务编译完模式之后,XMLBeans服务下载页就出现了,从这里我可以下载包括我的XMLBeans类型的JAR文件。默认文件名是xsdTypes.jar,但是在下载过程中,我将它重命名为bookTypes.jar。另外,我需要包含通用的XMLBeans支持代码的xmlbeans.jar文件。 那就它的全部东西了。你提供一个或多个模式,XMLBeans服务就返回一个包含你的类型的JAR文件。现在我准备创建一个地址簿应用,该应用处理来自于Java的XML地址簿和联系人。 AddressBookApp应用 AddressBookApp Java应用是一个简单的命令行应用。它提供了一个具有如下选项的菜单: 1. 打开地址簿 2. 打印所有联系人姓名 3. 打印所有联系人 4. 打印联系人 5. 根据姓名查找联系人 6. 根据地区码查找联系人 7. 根据州查找联系人 8. 从文件中添加联系人 9. 删除联系人 10.保存地址簿 11.退出 我将讲述上述这些功能的亮点,并利用代码片段来解释XMLBeans是如何被用来实现这些操作的。有些操作我没有提到,因为多个"打印"和"查找"操作彼此之间非常相似。 打开地址簿 此项操作的核心位于AddressBookApp的loadAddressBookFile方法中,其中一些代码如下所示: File bookFile = null; AddressBookDocument doc = null; AddressBook book = null; bookFile = new File(bookFilename); doc = (AddressBookDocument) XmlLoader.load(bookFile); book = doc.getAddressBook(); XmlLoader是基础XMLBeans类之一,它的加载方法是可以将XML文档读入XMLBeans类型系统的方式中的一种,利用这种方法可以通过XMLBeans API操作XML。上面的代码展示了一种使用XMLBeans加载XML文档的典型模式:调用XmlLoader的一个方法并且把结果强制转换到你正在加载的文档类型。在本例中是AddressBookDocument,这种类型代表一个与addressBook.xsd模式一致的XML文档。 当我第一次使用XMLBeans时,经常在这个地方遇到ClassCastException运行时异常的问题。这个异常总是意味着一种情况:指定的文档不是一个有效的模式实例,强制转换的目标类型(在我的例子中是AddressBookDocument)就是在从这里生成的。如果你遇到过这种错误,不要逐个模式地关注你尝试加载的实例文档的结构。要特别注意在模式和实例文档两者中的命名空间声明。利用像XML Spy这样的第三方模式敏感(schema-aware)XML工具非常有用。 一旦文档被成功地加载和强制转换,我就可以只调用AddressBookDocument的getAddressBook,来获得表示文件中<address-book>元素的XMLBean。我获得的AddressBook Java对象是应用程序中所有其他操作执行的对象。 注意,当我使用基于文件的方法加载XML文档时,XMLBeans也提供了从流中加载XML文档的方法。 打印所有联系人姓名 该操作调用AddressBookApp的 printAddressBookNames的方法,核心代码如下所示: Contact contact = null; int numRecs; int i; numRecs = book.sizeOfContactArray(); for (i=0; i<numRecs; i++) { contact = book.getContactArray(i); System.out.println((i+1) + ": " + getFormattedContactName(contact)); } Contact是表示<contact>元素的XMLBeans Java类型。我调用AddressBook类的 sizeOfContactArray方法来找出有多少<contact>元素以<address-book>元素的子元素存在,其中<address-book>元素由book变量表示。然后对所有<contact>元素都照此办理,为每个联系人打印AddressBookApp的getFormattedContactName方法的结果。getFormattedContactName包括下列代码: String familyName = contact.getFamilyName(); String givenName = contact.getGivenName(); return new String( ((familyName == null) ? "[no family-name]" : familyName) + ", " + ((givenName == null) ? "[no given-name]" : givenName)); 最重要的部分是头两行,在这两行里我调用Contact类的getFamilyName和getGivenName方法来获得<contact>元素的子元素<family-name> 和 <given-name>字符串的值。 联系人的列表在打印之前没有保存,把它留下给用户作为练习用。我可以给出一点提示,即XMLBeans的XQuery能力对于实现这一目的很有用。 希望你已经开始意识到XMLBeans是很直观的。生成的Java类型和在模式中定义的XML元素有同样的名称,这一点仅限于"java-fied"中。如果你熟悉XML文档的结构,那么就不难理解Java中XML文档的结构了。 根据名字查找联系人 这步操作会提示用户输入搜索字符串,然后打印出所有<address-book>中<contact>中的名字,在<contact>中包含了搜索字符串。代码如下: inputStr = getStringInput("Enter search string:").toLowerCase(); if (inputStr != null) { numContacts = _currentBook.sizeOfContactArray(); for (i=0; i<numContacts; i++) { contact = _currentBook.getContactArray(i); if (getFormattedContactName(contact). toLowerCase(). indexOf(inputStr) != -1) { System.out.println((i+1) + ": " + getFormattedContactName(contact)); } } } 这段代码非常简单。通过循环扫描<address-book>中的所有<contact>,检查对应各个联系人的getFormattedContactName返回的字符串是否包含了要搜索的那个字符串。这里之所以要使用getFormattedContactName函数,是因为这个函数可以方便地返回既包含了<family-name>元素又包含了<given-name>元素的字符串。注意,XMLBeans包含了XQuery功能,这样就可以使所有"查找"操作快速执行,不过,这些我要留到其他文章里讲。 从文件中添加联系人 这步操作会提示用户XML的文件名应该符合contactUsa.xsd模式,然后调用AddressBookApp的loadContactFile方法,这个方法和上面在"打开地址簿"部分所描述的loadAddressBookFile方法非常相似。 当新的<contact>元素被成功地载入到一个Contact XMLBeans对象中时,AddressBookApp的addNewContact方法会将其添加到<address-book>中,代码如下: int numRecs; int i; MailingAddress addr, newAddr; PhoneNumber phoneNum, newPhoneNum; Contact newContact = _currentBook.addNewContact(); newContact.setFamilyName(contact.getFamilyName()); newContact.setGivenName(contact.getGivenName()); numRecs = contact.sizeOfMailingAddressArray(); for (i=0; i<numRecs; i++) { newAddr = contact.getMailingAddressArray(i); addr = newContact.addNewMailingAddress(); if (newAddr.isSetLocation()) { addr.setLocation(newAddr.getLocation()); } if (newAddr.getAddressLine1() != null) { addr.setAddressLine1(newAddr.getAddressLine1()); } ... more of the same for other child elements } numRecs = contact.sizeOfPhoneNumberArray(); for (i=0; i<numRecs; i++) { newPhoneNum = contact.getPhoneNumberArray(i); phoneNum = newContact.addNewPhoneNumber(); if (newPhoneNum.isSetLocation()) { phoneNum.setLocation(newPhoneNum.getLocation()); } if (newPhoneNum.getAreaCode() != null) { phoneNum.setAreaCode(newPhoneNum.getAreaCode()); } if (newPhoneNum.getLocalPhoneNumber() != null) { phoneNum.setLocalPhoneNumber( newPhoneNum.getLocalPhoneNumber()); } } 这段代码用于替代XMLBeans的一个特性,在写这篇文章的时候,该特性还没有实现(XMLBeans当前还只有测试版的代码)。不过代码倒是很是简单:只是遍历树并传送来自元素及其属性的值,通过下面一行代码就可以最终实现这步操作: book.setContact(newContact); 删除联系人 这是所有操作中最简单的操作。首先提示用户需要删除<contact>的索引,接着调用_currentBook.removeContact(index-1)函数,该函数将从<address-book>元素中删除指定的<contact>子元素。这里之所以要将用户提供索引减1,是因为为了方便起见,应用程序的用户接口的索引是基于1的。 保存地址簿 最后一步操作将<address-book>元素的当前状态写入到一个由用户提供名称的文件中。下面是相应的代码: File bookFile = new File(inputStr); PrintStream destStream = new PrintStream(new FileOutputStream(bookFile), false, "UTF-8"); destStream.println(""); HashMap propMap = new HashMap(); propMap.put(XmlOptions.SAVE_PRETTY_PRINT, null); propMap.put(XmlOptions.SAVE_PRETTY_PRINT_INDENT, new Integer(2)); String xmlText = _currentBook.xmlText(propMap); destStream.println(xmlText); destStream.close(); 这里我使用了一般的Java IO类创建了一个输出流,以后,XML文档将要写入到这个输入流中。注意,这里我指定了必须用编码("UTF-8")编写这个文档。XML文档的符号编码是个比较复杂的话题,所有这些都牵涉到国际化的问题。UTF是用于一种通用的安全的编码方式。 接下来打印<?xml?>声明,这些声明都写在每个XML文档的开头,没有顺序要求。 下一步是生成实际的XML文本,该文本将被写入文件中。为完成这步操作,这里调用了XmlObject(所有XMLBeans类的基类)的 xmlText方法。xmlText方法通过选项的选项映像来控制它的行为。我使用SAVE_PRETTY_PRINT选项来请求人类可识别的格式化,并指定了SAVE_PRETTY_PRINT_INDENT选项,表示我希望有多种级别的XML结构以供选择,而不仅仅是只有两种选择。 最后,将XML文本写入到输出文件,接着关闭该文件。 编译AddressBookApp应用程序 运行应用程序是非常简单的: javac -classpath "bookTypes.jar;xmlbeans.jar" address\AddressBookApp.java (显然,在Unix/Linux中,符号"\"应改为"/") 在类路径中,惟一要添加的就是bookTypes.jar(即包含了按照我自己的模式生成的类型的JAR文件)和xmlbeans.jar(即包含了一般XMLBean支持的代码的JAR文件)。 注意,XMLBeans需要Java 2, Standard Edition (J2SE) 1.4环境的支持。 运行AddressBookApp应用程序 运行app也很简单: java -cp ".;./bookTypes.jar;./xmlbeans.jar" address.AddressBookApp ZIP文件里包含了实例代码,同时还包含了四个contact XML示例文件和两个示例地址名册:testbook.xml和fullbook.xml。testbook.xml仅包含在contactSmithers.xml中定义的联系人,fullbook.xml包含所有四个示例联系人。这些文件给了你足够的资料,通过这些资料你可以对应用程序中的所有可用操作进行试验。 结论 相信这个实例已经向我们展示了用XMLBeans处理XML是多么简单。我鼓励你下载实例代码并进行试验。然后用你自己的模式试一试。 我特意使这个实例相对简单一些,而更多地关注XMLBean根据你自己的模式所生成的特定模式的API。关于XMLBeans还有更多的内容,比如它可以操纵无相关模式的XML文档,可以使用XQuery在XML上执行复杂搜索和变换,还有其他一些功能。 |
XMLBEANS简单例子 - 愛芬資料庫 - CSDNBlog
例子中MySchema是继承BaseSchema的。
Schema:
BaseSchema.xsd
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/BaseSchema"
xmlns:tns="http://www.example.org/BaseSchema"
elementFormDefault="qualified">
<xs:complexType name="BaseSchema">
<xs:attribute name="id" type="xs:string" />
</xs:complexType>
</xs:schema>
MySchema.xsd
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/MySchema"
xmlns:tns="http://www.example.org/MySchema"
xmlns:b="http://www.example.org/BaseSchema"
elementFormDefault="qualified">
<xs:import namespace="http://www.example.org/BaseSchema" />
<xs:complexType name="MySchema">
<xs:complexContent>
<xs:extension base="b:BaseSchema">
<xs:sequence>
<xs:element name="name" type="xs:string" />
</xs:sequence>
</xs:extension>
</xs:complexContent>
</xs:complexType>
</xs:schema>
Ant:
build.xml
<?xml version="1.0" encoding="UTF-8"?>
<project name="MySchema" basedir="." default="build.schema">
<property environment="env" />
<property name="xmlbeans.home" value="${env.XMLBEANS_HOME}" />
<property name="xmlbeans.lib" value="${xmlbeans.home}\lib" />
<echo message="xmlbeans.home: ${xmlbeans.home}" />
<echo message="xmlbeans.home: ${xmlbeans.lib}" />
<target name="init">
<delete dir="build" />
<path id="xmlbeans.classpath">
<fileset dir="${xmlbeans.lib}"
includes="xbean.jar,xmlbeans-qname.jar,jsr173_1.0_api.jar" />
</path>
<taskdef name="scomp"
classname="org.apache.xmlbeans.impl.tool.XMLBean"
classpathref="xmlbeans.classpath" />
<mkdir dir="build" />
</target>
<target name="build.base" depends="init">
<scomp schema="schema/BaseSchema.xsd"
destfile="build/BaseSchema.jar">
<classpath>
<path refid="xmlbeans.classpath" />
</classpath>
</scomp>
</target>
<target name="build.schema" depends="init,build.base">
<scomp schema="schema/MySchema.xsd"
destfile="build/MySchema.jar">
<classpath>
<pathelement location="build/BaseSchema.jar" />
<path refid="xmlbeans.classpath" />
</classpath>
</scomp>
</target>
</project>
Trackback: http://tb.blog.csdn.net/TrackBack.aspx?PostId=1726600
Friday, November 16, 2007
用JAVA和XML构建分布式系统 - 中文JAVA技术网
用JAVA和XML构建分布式系统
阅读次数: 2135次
发布时间: 2002-02-02 00:00:00发布人: 中国计算机世界
来源:
可扩展标记语言(XML)作为一种简单的、中性的、易读的数据表示形式已经变得越来越流行,许多软件厂商宣布的“支持XML",意味着他们的产品将能生成或处理XML数据。XML也被看作再企业间交换数据最佳格式。它允许企业在所交换的数据的XML的文档类型定义(Document Type Definitions,DTDs)或模式(Schema)上取得一致。这些DTDs或Schema是独立于企业使用的数据库模式的。
本文将用研究在不同计算机之间通讯与处理XML数据的分布式系统的构建方法,主要是运行在不同的虚拟机上的JAVA应用之间的XML通讯。
XML通讯
万维网协会(World Wide Web Consortium, W3C)在XML规范中定义了XML的语法和语义。为了处理XML数据,XML文档必须经过解析。W3C定义了文档对象模型(DOM),它是应用程序员处理XML数据的接口。DOM已经有包括JAVA在内的许多语言的实现。JAVA应用程序可以通过DOM API来访问XML数据。XML解析器将产生XML文档的DOM表示。
图1说明了处理XML文档的JAVA分布式应用的简单模型。这个模型假设数据可以从诸如关系数据库之类的数据源得到。JAVA代码处理数据并最终产生DOM表示,这些代码表示为图中的处理器。
处理器代码将DOM代表的XML数据传给发送者。发送者是与接收者进行XML数据通讯的JAVA代码。接收者JAVA代码来接受XML数据,产生DOM表示的数据并把它传送给另一个处理器。简而言之,发送者和接收者抽象了DOM表示的XML数据的通讯。
发送者和接收者不是在同一个JAVA虚拟机上执行的。他们是通过分布式系统的构件来相连的。无论是接收者还是发送者都既是客户端又是服务器端,两者的数据传输都是双向的。
Xbeans
就像将要看到的一样,在本文中描述的发送者和接收者的三种实现方法都都是通过Xbeans来实现。Xbeans是一种接受XML数据作为输入,处理这个输入然后向下一个Xbeans输出XML结果的软件构件。Xbeans的输入输出都是XML的DOM文档,亦即传送给Xbeans的不是需要XML解析器解析的字符串,而是通过W3C的标准DOM API解析成了文档对象。图2说明了一个Xbeans。
Xbeans是JavaBeans,支持封装、重用、连接和客户化Java代码。通过适当的一些Xbeans和JavaBeans的设计工具,我们就能编很少的代码构建非常有用的分布式应用。 Xbeans从IBM的XML的JAVA开发工具包而来,在其上作了少量修改以便更适合分布式的应用。Xbeans能够从www.Xbeans.org的开放源码项目中免费获得。
实现发送方和接收方
下面将介绍用JAVA实现发送者和接收者的三种不同的方法。然后对每种方法作一个简单的分析。
方法一:用标准的web 服务器
这种方法将只是简单的将XML作为文本发送给远程计算机上的web服务器。发送方必须将DOM表示的XML转化为文本来与接收方进行通讯。然后,接受方必须将文本还原为DOM表示,如图3:
以下代码段用HTTP来实现发送者。这里用到了IBM Java开发包中的DOMWriter类来实现DOM表示到文本XML表示的转换。
|
注意到以上的documentReady()方法用remoteURL属性得到服务器上的CGI脚本的URL。为了与HTTP兼容,CGI脚本类用字符串”Content-type: text/html"封装接收者的输出。这个脚本然后调用服务器上的the receiverMain()方法。 Main()函数只是简单的实例化接收者然后调用其receiveDocument()方法。
|
最后receiveDocument()方法的代码段将重新生成DOM表示以便进一步处理。这里用到了IBM的XML解析器。
|
方法二:通过JAVA远程方法调用串行化文档
这个方法通过JAVA远程方法调用(JAVA RMI)和DOM串行化(serialization)来从发送者向接收者传输XML DOM 文档。如图4:

以下代码用JAVA远程方法调用实现发送方与接受方的通讯.
|
以下是接受方的JAVA 远程方法调用的实现。setName()方法将接受这传送给RMI注册(registry),documentReady()方法仅仅将接收到的文档传送给下一个组件。
|
方法三:CORBA-IIOP
第三方法用CORBA-IIOP(CORBA over Internet Inter-ORB Protocol)来传输数据。对象管理组织(OMG)正在建议扩展接口定义语言(IDL)将XML数据类型包括进去。这样,将来CORBA产品将能传输XML数据。如图5所示:

以下的OMG IDL给出了发送者和接收者CORBA实现的接口。
|
以下代码用JAVA串行化DOM和CORBA实现发送者。
|
以下代码用JAVA串行化DOM和CORBA实现接收者。
|
分析:
测试表明,纯文本表示的XML要比DOM串行化表示性能更好。同时,解析DOM和文本所用的时间也要比用JAVA直接串行化和法串行化所用的时间少。
标准的web服务器方式的优势是其应用基础要广泛许多。CGI脚本能够在绝大多数web服务器上运行,而且,接受方能够很容易的通过URL标识。而对于RMI,则需要RMI注册。CORBA的解决办法则需要在服务器上安装对象请求代理(Object Request Broker,ORB ),而且,CORBA发送者的实现使用的是一个URL的命名模式而不是接收者的CORBA对象引用,用一个字符串与一个URL相联系,然后在客户端转化。
CORBA 和RMI支持JAVA 客户端到JAVA服务器的解决方案。没有CGI脚本也不需要从标准输入中读取编码异常。而且,不需要在发送者每次用XML通讯时都启动一个JAVA虚拟机。他们两则均支持接收者的自动激活。
JAVA RMI方式只能在JAVA代码之间工作,对于web服务器包括CORBA理论上能在任何编程语言之间通讯。对于JAVA串行化的DOM来说,即便是客户端和服务器端均需要是JAVA代码的要求不是问题,它还存在另外一个困难,即JAVA串行化要求客户端和服务器运行的是相同的DOM实现。
结论
正如上面所述,有许多方法可以实现在JAVA分布式应用中发送XML数据,每一种方法的性能和互操作性都是不同的。重要的是应该把XML通讯从分布式应用逻辑中抽取出来。也就是,实现发送和接受XML的代码应和应用逻辑的代码中分离出来。通过把代码打包成软件组件,就能够改变发送方和接受方的代码而不会影响到应用其余实现。
可扩展标记语言(XML)作为一种简单的、中性的、易读的数据表示形式已经变得越来越流行,许多软件厂商宣布的“支持XML",意味着他们的产品将能生成或处理XML数据。XML也被看作再企业间交换数据最佳格式。它允许企业在所交换的数据的XML的文档类型定义(Document Type Definitions,DTDs)或模式(Schema)上取得一致。这些DTDs或Schema是独立于企业使用的数据库模式的。
本文将用研究在不同计算机之间通讯与处理XML数据的分布式系统的构建方法,主要是运行在不同的虚拟机上的JAVA应用之间的XML通讯。
XML通讯
万维网协会(World Wide Web Consortium, W3C)在XML规范中定义了XML的语法和语义。为了处理XML数据,XML文档必须经过解析。W3C定义了文档对象模型(DOM),它是应用程序员处理XML数据的接口。DOM已经有包括JAVA在内的许多语言的实现。JAVA应用程序可以通过DOM API来访问XML数据。XML解析器将产生XML文档的DOM表示。
图1说明了处理XML文档的JAVA分布式应用的简单模型。这个模型假设数据可以从诸如关系数据库之类的数据源得到。JAVA代码处理数据并最终产生DOM表示,这些代码表示为图中的处理器。

处理器代码将DOM代表的XML数据传给发送者。发送者是与接收者进行XML数据通讯的JAVA代码。接收者JAVA代码来接受XML数据,产生DOM表示的数据并把它传送给另一个处理器。简而言之,发送者和接收者抽象了DOM表示的XML数据的通讯。
发送者和接收者不是在同一个JAVA虚拟机上执行的。他们是通过分布式系统的构件来相连的。无论是接收者还是发送者都既是客户端又是服务器端,两者的数据传输都是双向的。
Xbeans
就像将要看到的一样,在本文中描述的发送者和接收者的三种实现方法都都是通过Xbeans来实现。Xbeans是一种接受XML数据作为输入,处理这个输入然后向下一个Xbeans输出XML结果的软件构件。Xbeans的输入输出都是XML的DOM文档,亦即传送给Xbeans的不是需要XML解析器解析的字符串,而是通过W3C的标准DOM API解析成了文档对象。图2说明了一个Xbeans。

Xbeans是JavaBeans,支持封装、重用、连接和客户化Java代码。通过适当的一些Xbeans和JavaBeans的设计工具,我们就能编很少的代码构建非常有用的分布式应用。 Xbeans从IBM的XML的JAVA开发工具包而来,在其上作了少量修改以便更适合分布式的应用。Xbeans能够从www.Xbeans.org的开放源码项目中免费获得。
实现发送方和接收方
下面将介绍用JAVA实现发送者和接收者的三种不同的方法。然后对每种方法作一个简单的分析。
方法一:用标准的web 服务器
这种方法将只是简单的将XML作为文本发送给远程计算机上的web服务器。发送方必须将DOM表示的XML转化为文本来与接收方进行通讯。然后,接受方必须将文本还原为DOM表示,如图3:

以下代码段用HTTP来实现发送者。这里用到了IBM Java开发包中的DOMWriter类来实现DOM表示到文本XML表示的转换。
|
注意到以上的documentReady()方法用remoteURL属性得到服务器上的CGI脚本的URL。为了与HTTP兼容,CGI脚本类用字符串”Content-type: text/html"封装接收者的输出。这个脚本然后调用服务器上的the receiverMain()方法。 Main()函数只是简单的实例化接收者然后调用其receiveDocument()方法。
|
最后receiveDocument()方法的代码段将重新生成DOM表示以便进一步处理。这里用到了IBM的XML解析器。
|
方法二:通过JAVA远程方法调用串行化文档
这个方法通过JAVA远程方法调用(JAVA RMI)和DOM串行化(serialization)来从发送者向接收者传输XML DOM 文档。如图4:
以下代码用JAVA远程方法调用实现发送方与接受方的通讯.
|
以下是接受方的JAVA 远程方法调用的实现。setName()方法将接受这传送给RMI注册(registry),documentReady()方法仅仅将接收到的文档传送给下一个组件。
|
方法三:CORBA-IIOP
第三方法用CORBA-IIOP(CORBA over Internet Inter-ORB Protocol)来传输数据。对象管理组织(OMG)正在建议扩展接口定义语言(IDL)将XML数据类型包括进去。这样,将来CORBA产品将能传输XML数据。如图5所示:
以下的OMG IDL给出了发送者和接收者CORBA实现的接口。
|
以下代码用JAVA串行化DOM和CORBA实现发送者。
|
以下代码用JAVA串行化DOM和CORBA实现接收者。
|
分析:
测试表明,纯文本表示的XML要比DOM串行化表示性能更好。同时,解析DOM和文本所用的时间也要比用JAVA直接串行化和法串行化所用的时间少。
标准的web服务器方式的优势是其应用基础要广泛许多。CGI脚本能够在绝大多数web服务器上运行,而且,接受方能够很容易的通过URL标识。而对于RMI,则需要RMI注册。CORBA的解决办法则需要在服务器上安装对象请求代理(Object Request Broker,ORB ),而且,CORBA发送者的实现使用的是一个URL的命名模式而不是接收者的CORBA对象引用,用一个字符串与一个URL相联系,然后在客户端转化。
CORBA 和RMI支持JAVA 客户端到JAVA服务器的解决方案。没有CGI脚本也不需要从标准输入中读取编码异常。而且,不需要在发送者每次用XML通讯时都启动一个JAVA虚拟机。他们两则均支持接收者的自动激活。
JAVA RMI方式只能在JAVA代码之间工作,对于web服务器包括CORBA理论上能在任何编程语言之间通讯。对于JAVA串行化的DOM来说,即便是客户端和服务器端均需要是JAVA代码的要求不是问题,它还存在另外一个困难,即JAVA串行化要求客户端和服务器运行的是相同的DOM实现。
结论
正如上面所述,有许多方法可以实现在JAVA分布式应用中发送XML数据,每一种方法的性能和互操作性都是不同的。重要的是应该把XML通讯从分布式应用逻辑中抽取出来。也就是,实现发送和接受XML的代码应和应用逻辑的代码中分离出来。通过把代码打包成软件组件,就能够改变发送方和接受方的代码而不会影响到应用其余实现。
Friday, November 9, 2007
JSF与Struts的异同(转)-好学蜘蛛 - 新浪BLOG
Struts和JSF/Tapestry都属于表现层框架,这两种分属不同性质的框架,后者是一种事件驱动型的组件模型,而Struts只是单纯的MVC模式框架,老外总是急吼吼说事件驱动型就比MVC模式框架好,何以见得,我们下面进行详细分析比较一下到底是怎么回事?
首先事件是指从客户端页面(浏览器)由用户操作触发的事件,Struts使用Action来接受浏览器表单提交的事件,这里使用了Command模式,每个继承Action的子类都必须实现一个方法execute。
在struts中,实际是一个表单Form对应一个Action类(或DispatchAction),换一句话说:在Struts中实际是一个表单只能对应一个事件,struts这种事件方式称为application
event,application event和component
event相比是一种粗粒度的事件。
struts重要的表单对象ActionForm是一种对象,它代表了一种应用,这个对象中至少包含几个字段,这些字段是Jsp页面表单中的input字段,因为一个表单对应一个事件,所以,当我们需要将事件粒度细化到表单中这些字段时,也就是说,一个字段对应一个事件时,单纯使用Struts就不太可能,当然通过结合JavaScript也是可以转弯实现的。
而这种情况使用JSF就可以方便实现,
| <h:inputText id="userId" value="#{login.userId}"> <f:valueChangeListener type="logindemo.UserLoginChanged" /> </h:inputText> |
#{login.userId}表示从名为login的JavaBean的getUserId获得的结果,这个功能使用struts也可以实现,name="login"
property="userId"
关键是第二行,这里表示如果userId的值改变并且确定提交后,将触发调用类UserLoginChanged的processValueChanged(...)方法。
JSF可以为组件提供两种事件:Value Changed和 Action.
前者我们已经在上节见识过用处,后者就相当于struts中表单提交Action机制,它的JSF写法如下:
| <h:commandButton id="login" commandName="login"> <f:actionListener type=”logindemo.LoginActionListener” /> </h:commandButton> |
从代码可以看出,这两种事件是通过Listerner这样观察者模式贴在具体组件字段上的,而Struts此类事件是原始的一种表单提交Submit触发机制。如果说前者比较语言化(编程语言习惯做法类似Swing编程);后者是属于WEB化,因为它是来自Html表单,如果你起步是从Perl/PHP开始,反而容易接受Struts这种风格。
基本配置
Struts和JSF都是一种框架,JSF必须需要两种包JSF核心包、JSTL包(标签库),此外,JSF还将使用到Apache项目的一些commons包,这些Apache包只要部署在你的服务器中既可。
JSF包下载地址:http://java.sun.com/j2ee/javaserverfaces/download.html选择其中Reference
Implementation。
JSTL包下载在http://jakarta.apache.org/site/downloads/downloads_taglibs-standard.cgi
所以,从JSF的驱动包组成看,其开源基因也占据很大的比重,JSF是一个SUN伙伴们工业标准和开源之间的一个混血儿。
上述两个地址下载的jar合并在一起就是JSF所需要的全部驱动包了。与Struts的驱动包一样,这些驱动包必须位于Web项目的WEB-INF/lib,和Struts一样的是也必须在web.xml中有如下配置:
| <web-app> <servlet> <servlet-name>Faces Servlet</servlet-name> <servlet-class>javax.faces.webapp.FacesServlet</servlet-class> <load-on-startup>1</load-on-startup> </servlet> <servlet-mapping> |
这里和Struts的web.xml配置何其相似,简直一模一样。
正如Struts的struts-config.xml一样,JSF也有类似的faces-config.xml配置文件:
<faces-config> <navigation-rule> <from-view-id>/index.jsp</from-view-id> <navigation-case> <from-outcome>login</from-outcome> <to-view-id>/welcome.jsp</to-view-id> </navigation-case> </navigation-rule> <managed-bean>
|
在Struts-config.xml中有ActionForm
Action以及Jsp之间的流程关系,在faces-config.xml中,也有这样的流程,我们具体解释一下Navigation:
在index.jsp中有一个事件:
<h:commandButton label="Login" action="login" />
action的值必须匹配form-outcome值,上述Navigation配置表示:如果在index.jsp中有一个login事件,那么事件触发后下一个页面将是welcome.jsp
JSF有一个独立的事件发生和页面导航的流程安排,这个思路比struts要非常清晰。
managed-bean类似Struts的ActionForm,正如可以在struts-config.xml中定义ActionForm的scope一样,这里也定义了managed-bean的scope为session。
但是如果你只以为JSF的managed-bean就这点功能就错了,JSF融入了新的Ioc模式/依赖性注射等技术。
Ioc模式
对于Userbean这样一个managed-bean,其代码如下:
public class UserBean {
private String name;
private String password;
// PROPERTY: name
public String getName() { return name; }
public void setName(String newValue) { name = newValue; }
// PROPERTY: password
public String getPassword() { return password; }
public void setPassword(String newValue) { password = newValue;
}
}
<managed-bean> |
faces-config.xml这段配置其实是将"me"赋值给name,将secret赋值给password,这是采取Ioc模式中的Setter注射方式。
Backing Beans
对于一个web
form,我们可以使用一个bean包含其涉及的所有组件,这个bean就称为Backing
Bean, Backing
Bean的优点是:一个单个类可以封装相关一系列功能的数据和逻辑。
说白了,就是一个Javabean里包含其他Javabean,互相调用,属于Facade模式或Adapter模式。
对于一个Backing
Beans来说,其中包含了几个managed-bean,managed-bean一定是有scope的,那么这其中的几个managed-beans如何配置它们的scope呢?
| <managed-bean> ... <managed-property> <property-name>visit</property-name> <value>#{sessionScope.visit}</value> </managed-property> |
这里配置了一个Backing
Beans中有一个setVisit方法,将这个visit赋值为session中的visit,这样以后在程序中我们只管访问visit对象,从中获取我们希望的数据(如用户登陆注册信息),而visit是保存在session还是application或request只需要配置既可。
UI界面
JSF和Struts一样,除了JavaBeans类之外,还有页面表现元素,都是是使用标签完成的,Struts也提供了struts-faces.tld标签库向JSF过渡。
使用Struts标签库编程复杂页面时,一个最大问题是会大量使用logic标签,这个logic如同if语句,一旦写起来,搞的JSP页面象俄罗斯方块一样,但是使用JSF标签就简洁优美:
<jia:navigatorItem name="inbox" label="InBox" |
如果authenticationBean中inboxAuthorized返回是假,那么这一行标签就不用显示,多干净利索!
先写到这里,我会继续对JSF深入比较下去,如果研究过Jdon框架的人,可能会发现,Jdon框架的jdonframework.xml中service配置和managed-bean一样都使用了依赖注射,看来对Javabean的依赖注射已经迅速地成为一种新技术象征,如果你还不了解Ioc模式,赶紧补课。
附Jsf核心教程一个JSF案例:login.rar